TL;DR: We present CompletionFormer, a hybrid architecture naturally benefits both the local connectivity of convolutions and the global context of the Transformer in one single model.
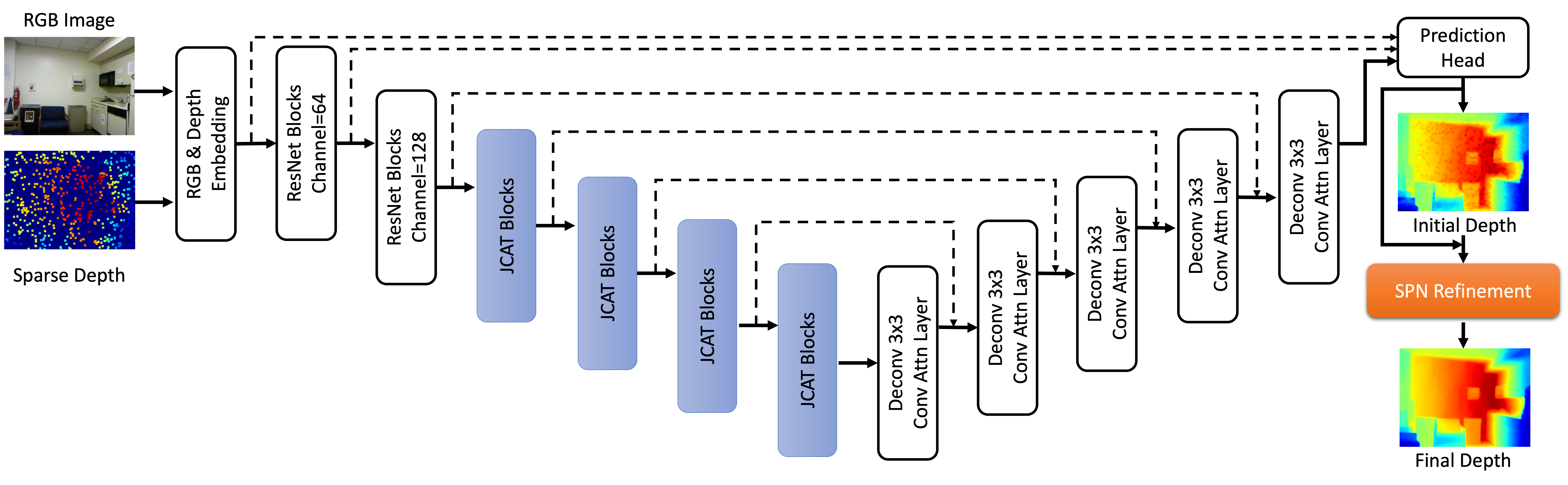
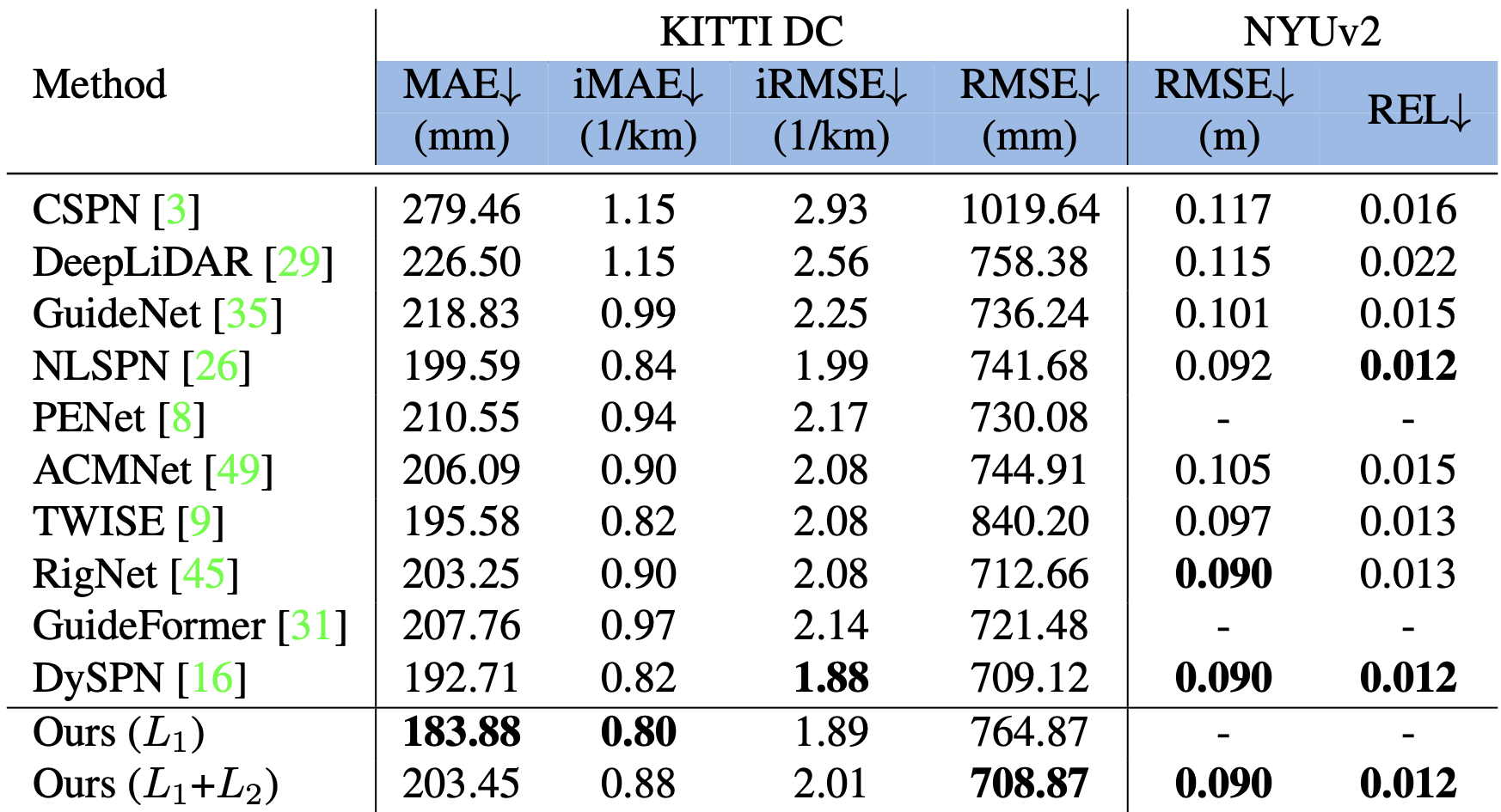
Given sparse depths and the corresponding RGB images, depth completion aims at spatially propagating the sparse measurements throughout the whole image to get a dense depth prediction. Despite the tremendous progress of deep-learning-based depth completion methods, the locality of the convolutional layer or graph model makes it hard for the network to model the long-range relationship between pixels. While recent fully Transformer-based architecture has reported encouraging results with the global receptive field, the performance and efficiency gaps to the well-developed CNN models still exist because of its deteriorative local feature details. This paper proposes a Joint Convolutional Attention and Transformer block (JCAT), which deeply couples the convolutional attention layer and Vision Transformer into one block, as the basic unit to construct our depth completion model in a pyramidal structure. This hybrid architecture naturally benefits both the local connectivity of convolutions and the global context of the Transformer in one single model. As a result, our CompletionFormer outperforms state-of-the-art CNNs-based methods on the outdoor KITTI Depth Completion benchmark and indoor NYUv2 dataset, achieving significantly higher efficiency (nearly 1/3 FLOPs) compared to pure Transformer-based methods.
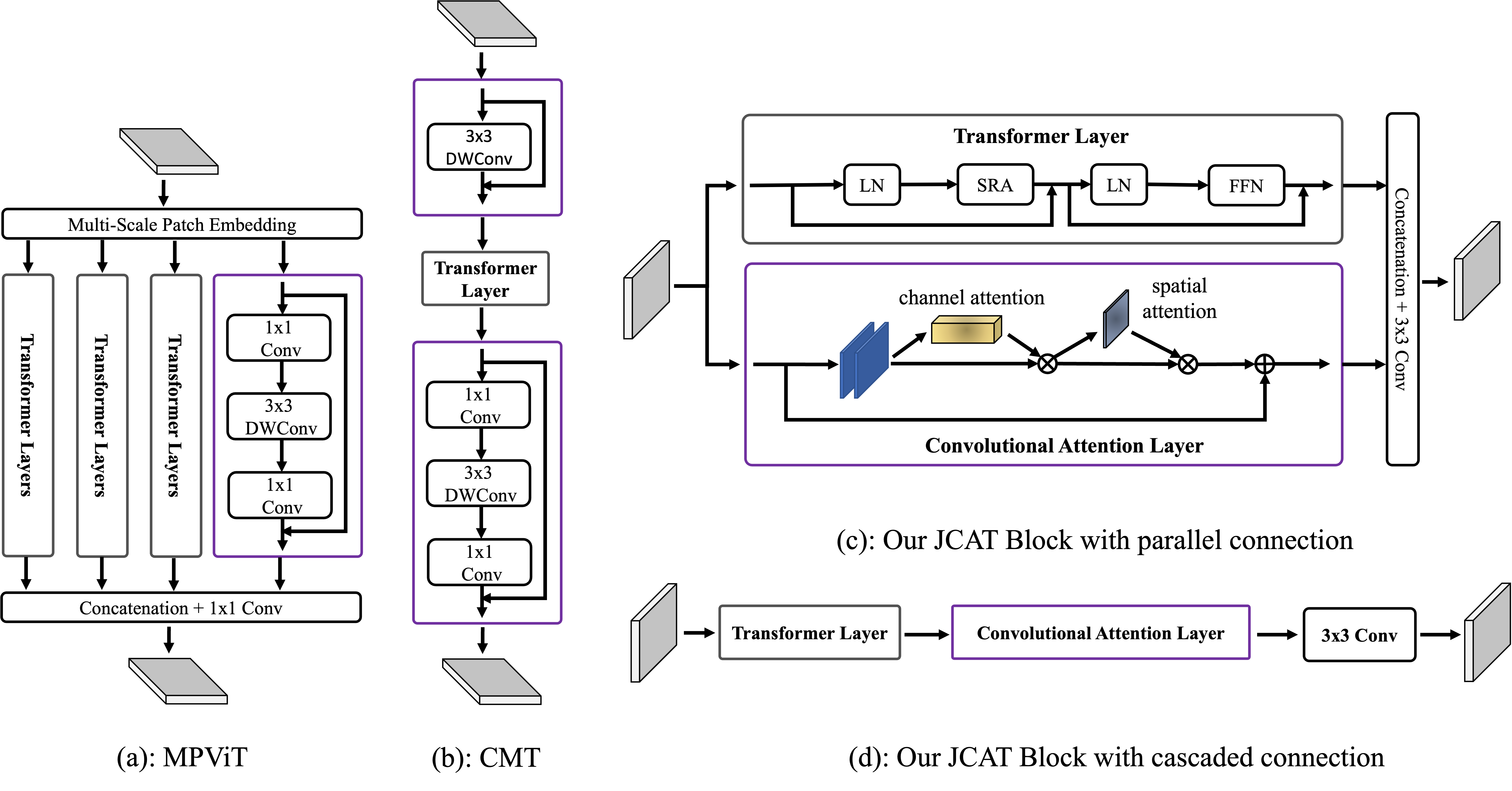
Example of architecture with convolutions and Vision Transformer. (a) Multi-Path Transformer Block of MPViT. (b) CMT Block of CMT-S. (c) Our proposed JCAT block which contains two parallel streams, i.e., convolutional attention and Transformer layer respectively. (d) The variant of our proposed block with cascaded connection.
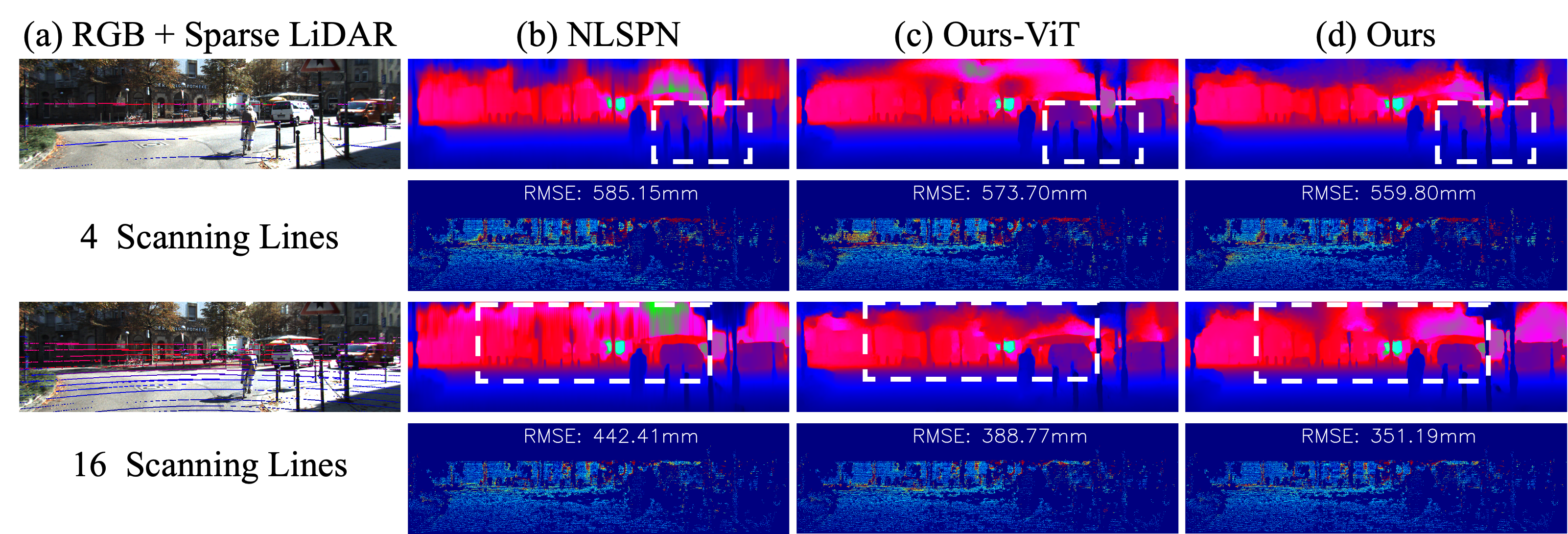
Qualitative results on KITTI DC selected validation dataset with 4 and 16 LiDAR scanning lines. We attach the subsampled LiDAR lines to the corresponding RGB image for better visualization. Ours-ViT denotes that only the Transformer layer is enabled in our proposed block. A colder color in depth and error maps denotes a lower value.
Qualitative results on NYUv2 dataset. Comparisons of our method against state-of-the-art method, i.e., NLSPN are presented. We provide RGB images, and dense predictions. The colder the colors of the error map, the lower the errors. Ours-ViT denotes that only the Transformer layer is enabled in our proposed block.
@inproceedings{zhang2023completionformer,
title={Completionformer: Depth completion with convolutions and vision transformers},
author={Zhang, Youmin and Guo, Xianda and Poggi, Matteo and Zhu, Zheng and Huang, Guan and Mattoccia, Stefano},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={18527--18536},
year={2023}
}