TL;DR:We present TemporalStereo, a coarse-to-fine stereo matching network that is highly efficient, and able to effectively exploit the past geometry and context information to boost matching accuracy.
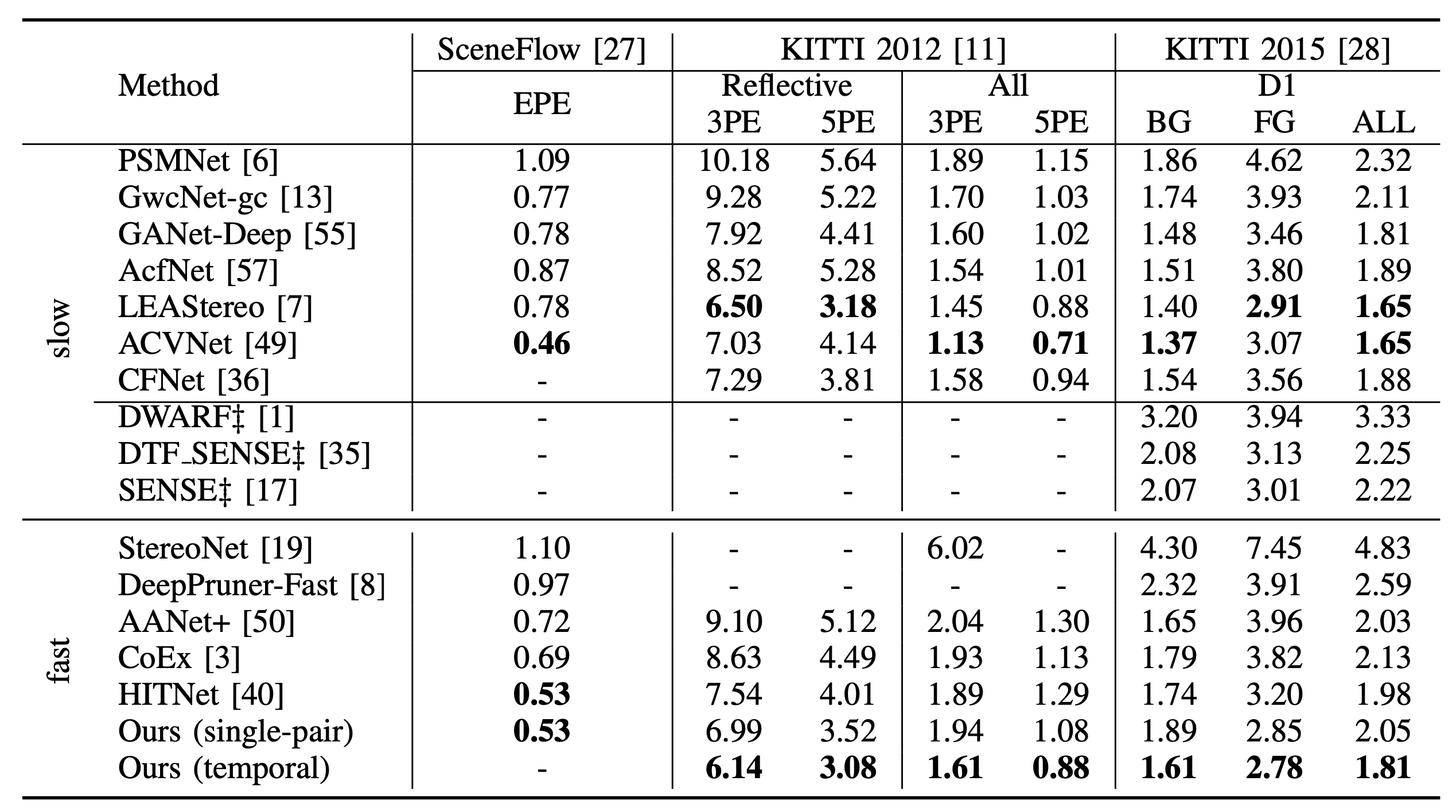
We present TemporalStereo, a coarse-to-fine stereo matching network that is highly efficient, and able to effectively exploit the past geometry and context information to boost matching accuracy. Our network leverages sparse cost volume and proves to be effective when a single stereo pair is given. However, its peculiar ability to use spatio-temporal information across stereo sequences allows TemporalStereo to alleviate problems such as occlusions and reflective regions while enjoying high efficiency also in this latter case. Notably, our model -- trained once with stereo videos -- can run in both single-pair and temporal modes seamlessly. Experiments show that our network relying on camera motion is robust even to dynamic objects when running on videos. We validate TemporalStereo through extensive experiments on synthetic (SceneFlow, TartanAir) and real (KITTI 2012, KITTI 2015) datasets. Our model achieves state-of-the-art performance on any of these datasets.
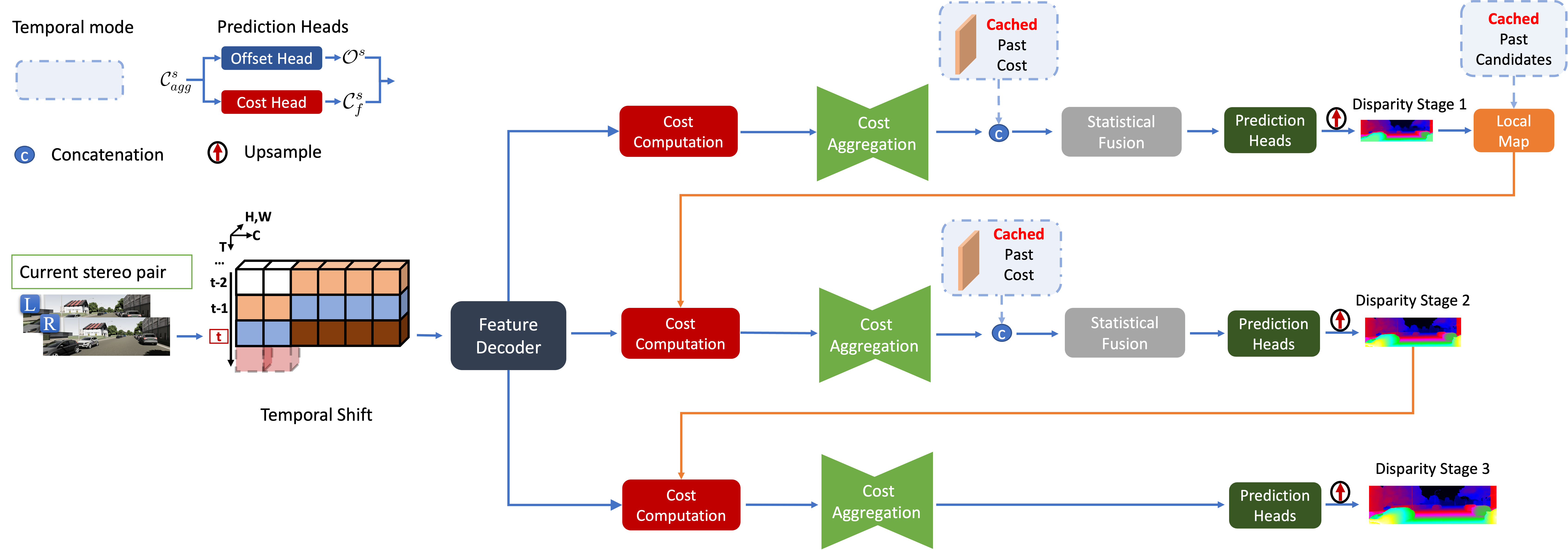
TemporalStereo Architecture. In single-pair mode, the model predicts the disparity map in a coarse-to-fine manner. If past pairs are available, the same model switches to temporal mode and employs features, costs, and candidates cached from past pairs to improve the current prediction.
We show the ground truth disparities and the predictions with and without adaptive shifting for three horizontal regions(i.e., A, B, C) and one pixel (D) in the image. For A, B, C, our strategy better estimates the actual disparity distributions. For D, the matching distribution of 5 disparity candidates switches from a flattened unimodal to one-hot distribution centered at ground truth by adaptively shifting candidates.
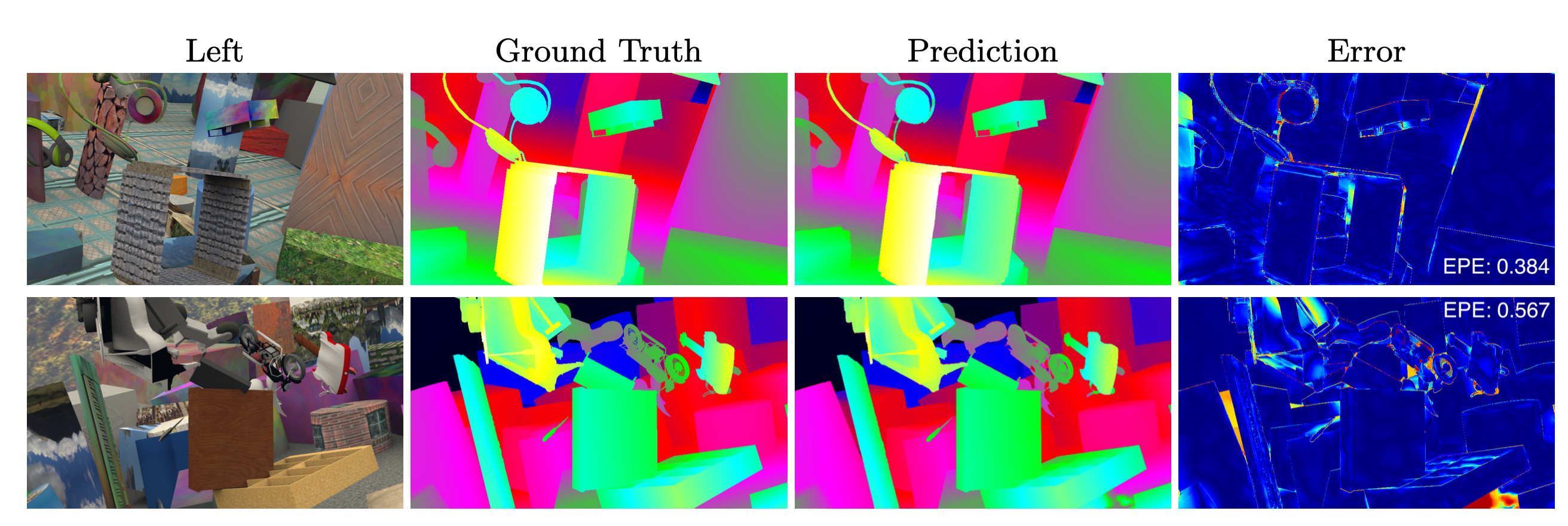
Qualitative results on SceneFlow. From left to right, the reference/left image, the ground truth disparity map, the prediction in single-pair mode and its error (darker the color, lower the error).
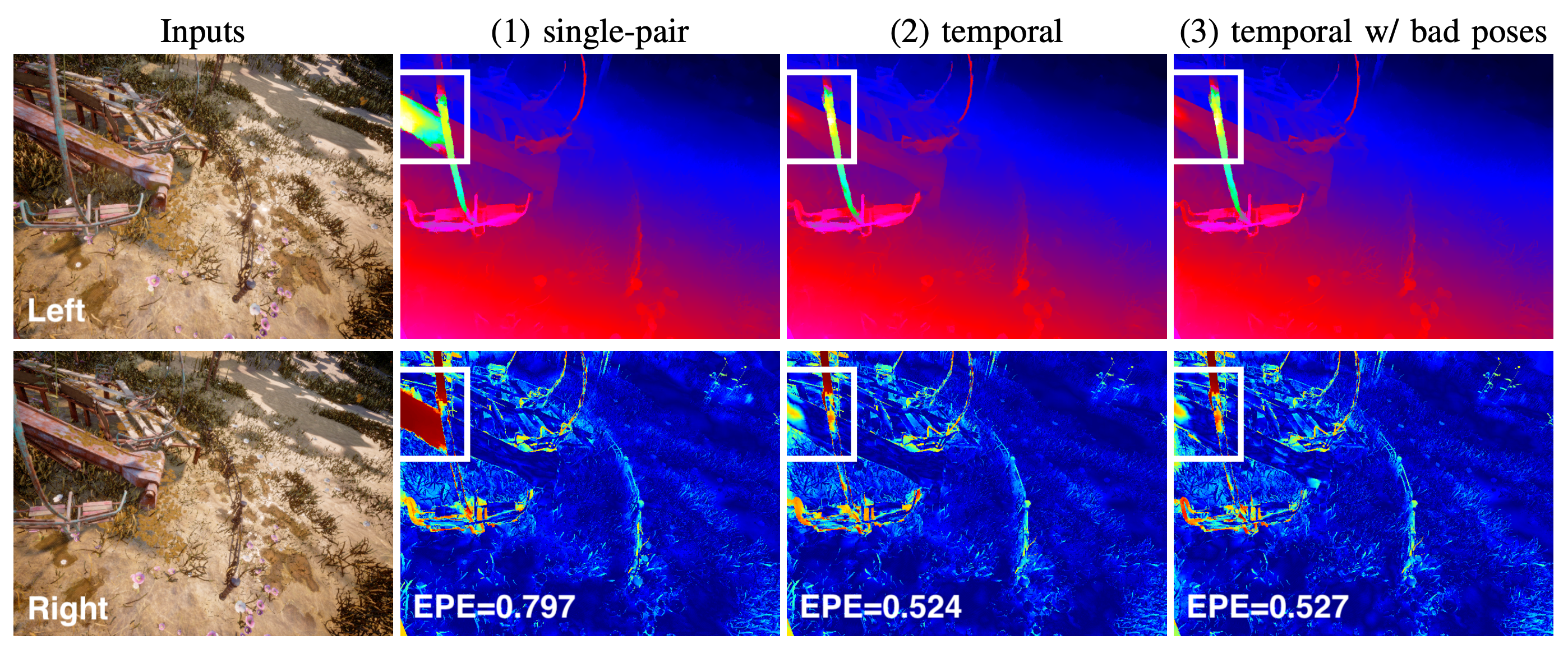
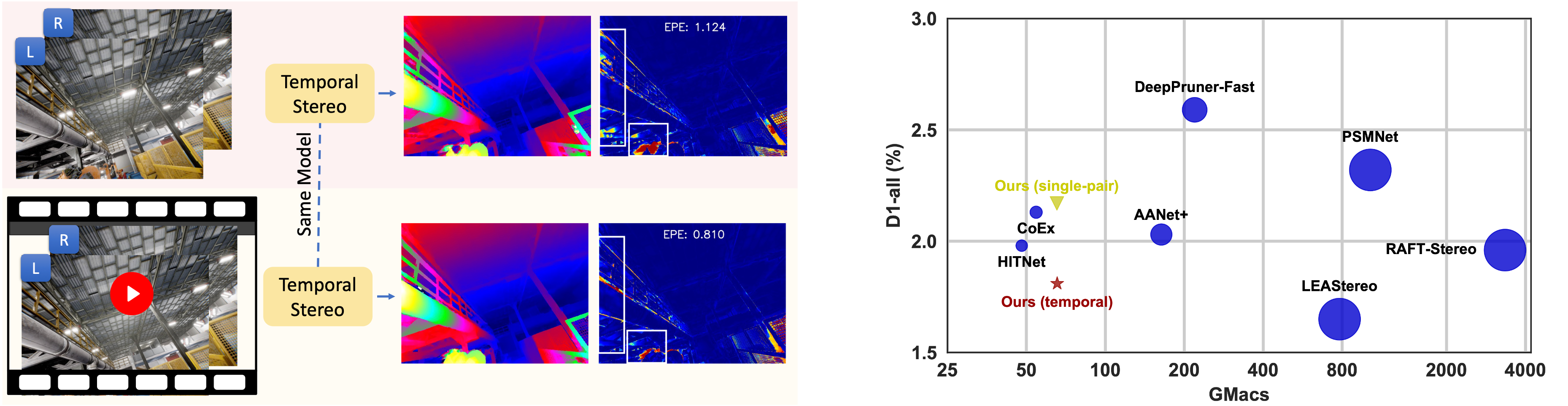
Compared to single-pair mode (1), temporal mode (2) is more accurate at occlusions, even with noisy poses (3) -- colder colors encode lower error.
Even without access to the ground truth pose, our TemporalStereo in temporal mode is robust to dynamic objects (e.g., pedestrians).
@proceedings{zhang2022temporalstereo,
title={TemporalStereo: Efficient Spatial-Temporal Stereo Matching Network},
author={Zhang, Youmin and Poggi, Matteo and Tosi, Fabio and Mattoccia, Stefano},
booktitle={IROS},
year={2023}
}